
Experiment #5.
Challenge:
Can multiple design agents regenerate a similar experience using nearly identical prompts?
If so, there may be more flexibility across tools and less rigidity in choosing a platform.
Theory:
If platforms are powered by the same underlying model family (e.g., Claude), then providing the same prompt and reference screen should produce comparable structural results.
Assumptions:
Prompt clarity is consistent.
Screenshot + instruction should anchor structural reconstruction.
Model parity may suggest similar behavior.
Differences, if present, would be incremental — not foundational.
AI Tools:
• Google Notebook
• Chat GPT
• Figma, Figma Make
Persona driven scenario:
Context: Booked lodging accessibility annotations
Persona: UX designer
Goal: Produce a web-ready screen from an existing screenshot with the intent of testing dynamic content.
What I started with
A post-booking lodging confirmation screen (mobile), used as the structural baseline.
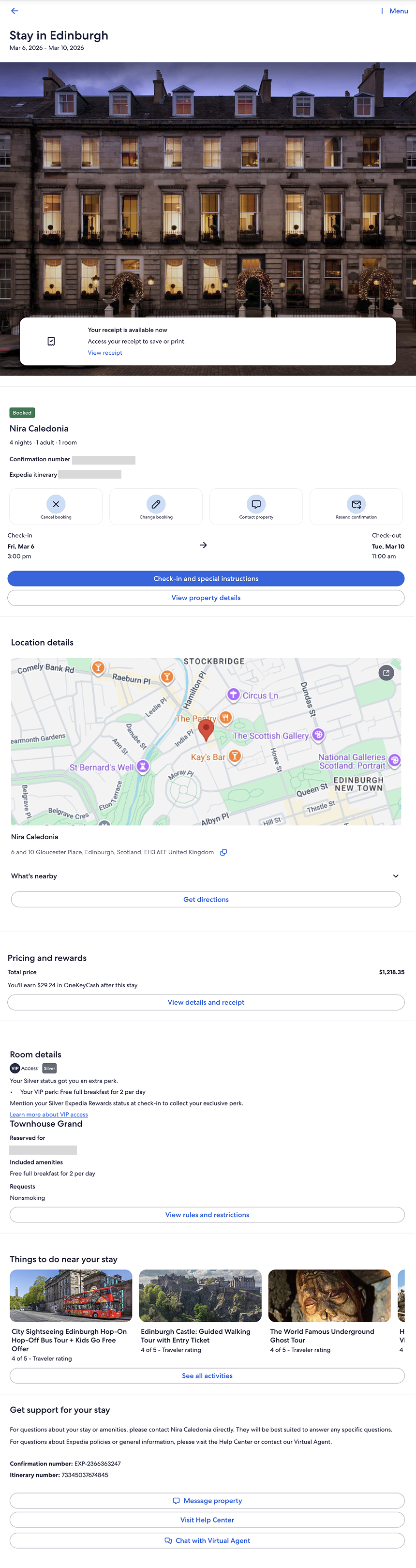
Prompt 1:
Asked Figma AI to generate a web-ready version of the booked stay confirmation screen.
Result:
The agent hallucinated a new layout. Only the image was reproduced accurately.
Test & Results

Prompt 2:
Explicitly instructed it to use the content and information from the provided screen and make it web-ready.
Result:
Again, the image was reproduced, but structural fidelity was not maintained.
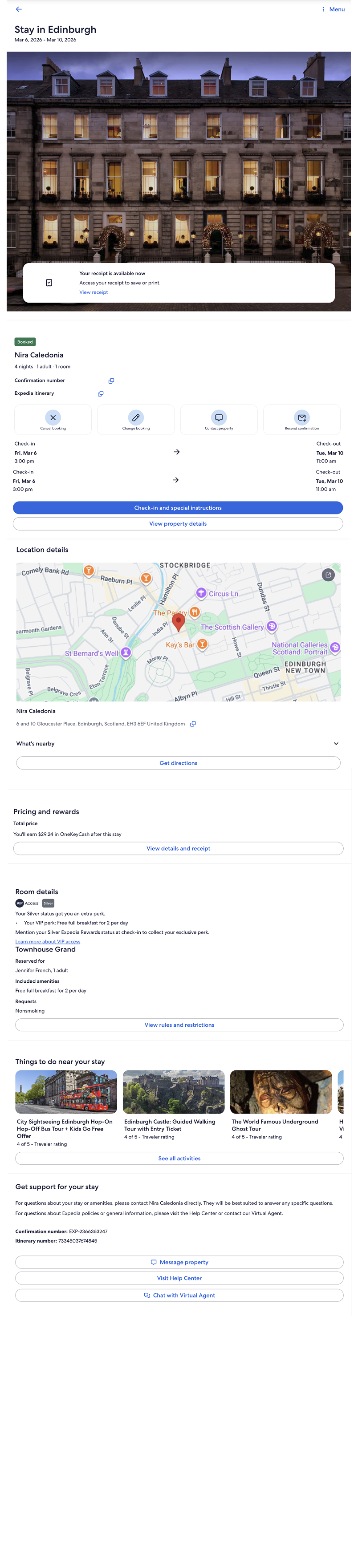
Prompt 3:
Asked it once more to create a web-ready screen.
Result:
It reproduced the output of the first prompt — repeating the hallucinated structure rather than regenerating from the reference.
Model parity does not equal workflow parity
The behavior was consistent — just not aligned with the goal.
Despite v0 (also Claude-powered) successfully reconstructing structure, Figma AI did not. This suggests that orchestration, tool constraints, and product design shape outcomes more than the underlying model alone.
Prompt portability has limitations.
Was this a successful experiment?
No. I was unable to generate a web-ready or Figma-ready screen (individual layers and frames) comparable to what UX Pilot and v0 produced. The outputs did not reconstruct structure or hierarchy in a meaningful way.
The experiment did not meet its intended outcome.
What surprised me?
The degree of hallucination.
Rather than approximating the provided screen, the agent generated an entirely new interpretation. The divergence was not subtle — it was structural.
What did I not expect?
The persistence of the hallucination.
Even after refining the prompt and explicitly instructing it to use the provided content and hierarchy, the output remained misaligned and repeated earlier interpretations.
What would I have done differently?
Given that I began with a screenshot — as I had successfully done in other experiments — I would not change the initial approach.
However, if Figma were the required tool, I would adjust the workflow. I would first prompt it to create a properly layered Figma file using the content and hierarchy from the screen capture. If that produced a structurally sound result, I would then prompt it to generate a web-ready version.
In this case, the limitation appears to be architectural rather than instructional.